Note
இந்தப் பக்கம் docs/tutorials/01_neural_networks.ipynb இலிருந்து உருவாக்கப்பட்டது.
குவாண்டம் நியூரல் நெட்வொர்க்குகள்#
கண்ணோட்டம்#
குறிப்பேடு.
பயிற்சி பின்வருமாறு கட்டப்பட்டிருக்கிறது:
முன்னுரை <#1.-Introduction>`__
எப்படி QNNகளை உடனுக்குடன் உருவாக்குவது
ஃபார்வர்டு பாஸை எப்படி இயக்குவது
எப்படி பேக்வர்ட் பாஸை இயக்குவது
மேம்பட்ட செயல்பாடு
முடிவு
1. முன்னுரை#
1.1 குவாண்டம் எதிராகக் கிளாசிக்கல் நியூரல் நெட்வொர்க்குகள்#
கிளாசிக்கல் நியூரல் நெட்வொர்க்குகள் மனித மூளையால் ஈர்க்கப்பட்ட அல்காரிதம் மாதிரிகள் ஆகும், அவை தரவுகளில் உள்ள வடிவங்களை அடையாளம் காணவும் கடினமான சிக்கல்களைத் தீர்க்க கற்றுக்கொள்ளவும் பயிற்சியளிக்கப்படுகின்றன. அவை ஒன்றோடொன்று இணைக்கப்பட்ட முனைகளின் வரிசையை அடிப்படையாகக் கொண்டவை, அல்லது நியூரான்கள், ஒரு அடுக்கு அமைப்பில் ஒழுங்கமைக்கப்பட்டவை, இயந்திரம் அல்லது ஆழ்ந்த கற்றல் பயிற்சி உத்திகளைப் பயன்படுத்துவதன் மூலம் கற்றுக்கொள்ளக்கூடிய அளவுருக்கள்.
குவாண்டம் மெஷின் லேர்னிங்கின் (க்யூஎம்எல்) உந்துதல், குவாண்டம் கம்ப்யூட்டிங் மற்றும் கிளாசிக்கல் மெஷின் லேர்னிங்கில் இருந்து புதிய மற்றும் மேம்படுத்தப்பட்ட கற்றல் திட்டங்களுக்கு வழி திறக்கும் கருத்துக்களை ஒருங்கிணைப்பதாகும். கிளாசிக்கல் நியூரல் நெட்வொர்க்குகள் மற்றும் அளவுருக் குவாண்டம் சுற்றுகளை இணைப்பதன் மூலம் QNNகள் இந்த பொதுவான கொள்கையைப் பயன்படுத்துகின்றன. அவை இரண்டு புலங்களுக்கு இடையில் ஒரு குறுக்குவெட்டில் இருப்பதால், QNNகளை இரண்டு கண்ணோட்டங்களில் பார்க்க முடியும்:
ஒரு இயந்திர கற்றல் கண்ணோட்டத்தில், QNNகள் மீண்டும் ஒருமுறை, அவற்றின் கிளாசிக்கல் சகாக்களுக்கு ஒத்த முறையில் தரவுகளில் மறைந்திருக்கும் வடிவங்களைக் கண்டறிய பயிற்சியளிக்கப்படும் அல்காரிதம் மாதிரிகள் ஆகும். இந்த மாதிரிகள் லோட் கிளாசிக்கல் தரவை (உள்ளீடுகள்) ஒரு குவாண்டம் நிலையில், பின்னர் செயல்படுத்தும் பயிற்சி செய்யக்கூடிய எடைகள் மூலம் குவாண்டம் கேட் அளவுருக்களுடன். தரவு ஏற்றுதல் மற்றும் செயலாக்க படிகள் உட்பட பொதுவான QNN உதாரணத்தை படம் 1 காட்டுகிறது. இந்த நிலையை அளப்பதன் மூலம் கிடைக்கும் வெளியீடு, பின் பரப்புதல் மூலம் எடைகளைப் பயிற்றுவிக்க இழப்புச் செயல்பாட்டில் செருகப்படலாம்.
ஒரு குவாண்டம் கம்ப்யூட்டிங் கண்ணோட்டத்தில், QNNகள் குவாண்டம் அல்காரிதங்கள் ஆகும், அவை அளவுரு குவாண்டம் சர்க்யூட்களை அடிப்படையாகக் கொண்டவை, அவை கிளாசிக்கல் ஆப்டிமைசர்களைப் பயன்படுத்தி மாறுபட்ட முறையில் பயிற்சியளிக்கப்படலாம். இந்த சுற்றுகள் படம் 1 இல் காணப்படுவது போல் அம்ச வரைபடம் (உள்ளீட்டு அளவுருக்களுடன்) மற்றும் ansatz (பயிற்சிக்கு ஏற்ற எடைகளுடன்) உள்ளன.

படம் 1. பொதுவான குவாண்டம் நியூரல் நெட்வொர்க் (QNN) அமைப்பு.
நீங்கள் பார்க்கிறபடி, இந்த இரண்டு முன்னோக்குகளும் ஒன்றுக்கொன்று நிரப்புகின்றன, மேலும் அவை "குவாண்டம் நியூரான்" அல்லது QNN இன் "அடுக்கு" போன்ற கருத்துகளின் கடுமையான வரையறைகளை நம்பியிருக்க வேண்டிய அவசியமில்லை.
1.2 கிஸ்கிட்-மெஷின்-லேர்னிங் இல் செயல்படுத்துதல்#
qiskit-machine-learning இல் உள்ள QNNகள் வெவ்வேறு பயன்பாட்டு நிகழ்வுகளுக்குப் பயன்படுத்தக்கூடிய பயன்பாட்டு-அஞ்ஞானக் கணக்கீட்டு அலகுகளாகக் குறிக்கப்படுகின்றன, மேலும் அவற்றின் அமைப்பு அவை தேவைப்படும் பயன்பாட்டைப் பொறுத்தது. தொகுதி QNNகளுக்கான இடைமுகம் மற்றும் இரண்டு குறிப்பிட்ட செயலாக்கங்களைக் கொண்டுள்ளது:
NeuralNetwork: நரம்பியல் நெட்வொர்க்குகளுக்கான இடைமுகம். இது அனைத்து QNNகளும் பெறப்பட்ட ஒரு சுருக்க வகுப்பாகும்.
EstimatorQNN: குவாண்டம் மெக்கானிக்கல் அவதானிப்புகளின் மதிப்பீட்டின் அடிப்படையில் ஒரு நெட்வொர்க்.
SamplerQNN: ஒரு சர்க்யூட் அளவை அளப்பதன் விளைவாக உருவான மாதிரிகளின் அடிப்படையில் ஒரு நெட்வொர்க்.
இந்தச் செயலாக்கங்கள் qiskit primitives ஐ அடிப்படையாகக் கொண்டவை. சிமுலேட்டர் அல்லது உண்மையான குவாண்டம் வன்பொருளில் QNNகளை இயக்குவதற்கான நுழைவுப் புள்ளியாக ப்ரிமிடிவ்கள் உள்ளன. ஒவ்வொரு செயலாக்கமும், EstimatorQNN மற்றும் SamplerQNN, அதனுடன் தொடர்புடைய பழமையான ஒரு விருப்ப நிகழ்வை எடுத்துக்கொள்கிறது, இது முறையே BaseEstimator மற்றும் BaseSampler இன் துணைப்பிரிவாக இருக்கலாம்.
qiskit.primitives தொகுதியானது ஸ்டேட்வெக்டர் உருவகப்படுத்துதல்களை இயக்க மாதிரி மற்றும் மதிப்பீட்டாளர் வகுப்புகளுக்கான குறிப்புச் செயலாக்கத்தை வழங்குகிறது. முன்னிருப்பாக, QNN வகுப்பிற்கு எந்த நிகழ்வும் அனுப்பப்படவில்லை எனில், அதனுடன் தொடர்புடைய முதன்மையான (Sampler அல்லது Estimator) ஒரு நிகழ்வு பிணையத்தால் தானாகவே உருவாக்கப்படும். ப்ரிமிடிவ்ஸ் பற்றிய கூடுதல் தகவலுக்கு, தயவு செய்து primitives documentation ஐப் பார்க்கவும்.
நியூரல்நெட்வொர்க் வகுப்பு என்பது கிஸ்கிட்-மெஷின்-லேர்னிங் இல் கிடைக்கும் அனைத்து QNNகளுக்கான இடைமுகமாகும். தரவு மாதிரிகள் மற்றும் பயிற்சியளிக்கக்கூடிய எடைகளை உள்ளீடாக எடுக்கும் முன்னோக்கி மற்றும் பின்தங்கிய பாஸை இது வெளிப்படுத்துகிறது.
நியூரல்நெட்வொர்க்கள் "நிலையற்றவை" என்பதைக் கவனத்தில் கொள்ள வேண்டியது அவசியம். அவற்றில் எந்தப் பயிற்சித் திறன்களும் இல்லை (இவை உண்மையான வழிமுறைகள் அல்லது பயன்பாடுகளுக்குத் தள்ளப்படுகின்றன: <https://qiskit.org/ecosystem/machine-learning/apidocs/qiskit_machine_learning.algorithms.html
இரண்டு நியூரல் நெட்வொர்க் செயல்படுத்தலுக்கான குறிப்பிட்ட உதாரணங்களை இப்போது பார்க்கலாம். ஆனால் முதலில், ரன்களுக்கு இடையில் முடிவுகள் மாறாமல் இருப்பதை உறுதிசெய்ய அல்காரிதம் விதையை அமைப்போம்.
[25]:
from qiskit_algorithms.utils import algorithm_globals
algorithm_globals.random_seed = 42
2. QNNகளை எவ்வாறு உடனடியாக உருவாக்குவது#
2.1. எஸ்டிமேட்டர்QNN#
` ` EstimatorQNN ` ` எடுத்துக்காட்டு ஒரு பராமரிப்பு வளிமண்டல சுற்றுச்சூழல் உள்ளீடு, மற்றும் ஒரு விருப்பமான கோட்பாடு යාන්ත්රික கணக்கீடும், மற்றும் முன்னணி மதிப்பு கணக்கீடுகளின் மதிப்பு கணக்கீடுகள். ` ` EstimatorQNN ` ` மேலும் சிக்கலான QNNகளை உருவாக்க ஆவணங்களின் பட்டியல்களை ஏற்றுக்கொள்கிறது.
ஒரு எளிய எடுத்துக்காட்டு நடவடிக்கையில் ` ` EstimatorQNN ` ` பார்க்கலாம். நாம் பராமரிப்பு சுற்றுப்பாதை கட்டி தொடங்கினோம். இந்த குவாண்ட் சுற்றுச்சொல் இரண்டு அளபுருக்கள் கொண்டது, ஒரு QNN உள்ளீட்டை குறிக்கும் மற்றொன்று ஒரு சுழல் எடை குறிக்கிறது:
[26]:
from qiskit.circuit import Parameter
from qiskit import QuantumCircuit
params1 = [Parameter("input1"), Parameter("weight1")]
qc1 = QuantumCircuit(1)
qc1.h(0)
qc1.ry(params1[0], 0)
qc1.rx(params1[1], 0)
qc1.draw("mpl")
[26]:
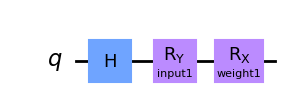
நாம் இப்பொழுது எதிர்பார்ப்பு மதிப்பு கணக்கெடுப்பை வரையறுக்கப்பட முடியும். அமைக்கப்படவில்லை என்றால், ` ` EstimatorQNN ` ` தானாகவே முன்னிருப்பாக :math:` Z ^ {otimes n} . இங்கு, :math: n `. குவாண்ட் சுற்றுப்பின் எண்ணிக்கை.
இந்த உதாரணத்தில், நாம் விஷயத்தை மாற்ற மற்றும் :math:` Y ^ {otimes n} ` பார்வை:
[27]:
from qiskit.quantum_info import SparsePauliOp
observable1 = SparsePauliOp.from_list([("Y" * qc1.num_qubits, 1)])
மேலே வரையறுக்கப்பட்ட குவாண்டம் சுற்றியோடு, மற்றும் நாம் உருவாக்க முடியும், ` ` EstimatorQNN ` ` கட்டமைப்புகள் பின்வரும் விசைப்புச் சொற்களில் எடுத்துக்கொள்கிறது:
மதிப்பீடு: விருப்பமான பழமையான நிகழ்வுinput_params: "நெட்வொர்க் உள்ளீடுகள்" எனக் கருதப்பட வேண்டிய குவாண்டம் சர்க்யூட் அளவுருக்களின் பட்டியல்weight_params: "நெட்வொர்க் எடைகள்" எனக் கருதப்பட வேண்டிய குவாண்டம் சர்க்யூட் அளவுருக்களின் பட்டியல்
இந்த உதாரணத்தில், "பரம்ஸ்1"-இன் முதல் அளவுரு உள்ளீடாகவும், இரண்டாம் அளவுரு எடையாகவும் இருக்கவேண்டுமென்று தீர்மானித்தோம். நாம் உள்ளூர் ஸ்டேட்வெக்டர் ஒப்புருவாக்கி பயன்படுத்தும்போது, "எஸ்டிமேடர்" அளவுரை அமைக்கபடாது; வலைப்பின்னல் "எஸ்டிமேடர்" ப்ரிமிட்டிவ் குறிப்பை இன்ஸ்டன்ஸ்-ஆக நமக்கு உருவாக்கும். நாம் கிளவுட் வளங்களை அல்லது "ஏர்" ஒப்புருவாக்கி அணுக வேண்டுமென்றால், "எஸ்டிமேடர்" இன்ஸ்டன்ஸ்-ஐ வரையறுத்து "எஸ்டிமேடர் க்யூ எண் எண்"-ுக்கு அனுப்ப வேண்டும்.
[28]:
from qiskit_machine_learning.neural_networks import EstimatorQNN
estimator_qnn = EstimatorQNN(
circuit=qc1, observables=observable1, input_params=[params1[0]], weight_params=[params1[1]]
)
estimator_qnn
[28]:
<qiskit_machine_learning.neural_networks.estimator_qnn.EstimatorQNN at 0x7fd668ca0e80>
பின்வரும் பகுதிகளில் QNN (QNN) பயன்படுத்த எப்படி பார்க்க வேண்டும், ஆனால் அந்த முன், ` சம்ப்லெர்க் QNN ` ` வகுப்பை வெளியே சரிபார்க்கலாம்.
2.2. சாமப்லர்QNN#
` ` SamplerQNN ` ` ` EstimatorQNN ` `, ஆனால் அது நேரடியாக மாதிரிகளில் இருந்து மாதிரிகளை ஏற்றுக்கொள்ளும் ஏனெனில், அது ஒரு வழக்கமான ஒத்திசைவு தேவை இல்லை.
இந்த வெளியீட்டு மாதிரிகளை ஒரு பிட்வரிசைக்கு ஒதுக்கப்பட்ட முழு அட்டவணை அளவுகோள்களின் இயல்புகளாக முன்னிருப்பாக வரையறுக்கப்படுகிறது. எனினும், ` ` சாம்பல்QNN ` ` கூட மாதிரிகளை புதுப்பிக்கப்படுவதற்கு ` ` தவிர்க்க ` ` குறிப்பிடுவதற்கு உதவுகிறது. இந்த செயல்கூறு வரையறுக்கப்படவேண்டும் அதனால் அது அளவிடப்பட்ட முழு (பிட்ரசில் இருந்து) மற்றும் அதை ஒரு புதிய மதிப்பு, அதாவது, எதிர்மறை எண்ணை வரையறுக்கிறது.
(!) தனிப்பயன் விளக்கம் செயல்பாடு வரையறுக்கப்பட்டால், அவுட்புட்_ஷேப் பிணையத்தால் ஊகிக்கப்படாது, மேலும் வெளிப்படையாக வழங்கப்பட வேண்டும்.
(!) விளக்கம் செயல்பாடு பயன்படுத்தப்படாவிட்டால், நிகழ்தகவு வெக்டரின் பரிமாணம் குவிட்களின் எண்ணிக்கையுடன் அதிவேகமாக அளவிடப்படும் என்பதையும் நினைவில் கொள்ள வேண்டியது அவசியம். தனிப்பயன் விளக்கம் செயல்பாட்டின் மூலம், இந்த அளவிடுதல் மாறலாம். எடுத்துக்காட்டாக, ஒரு குறியீட்டை தொடர்புடைய பிட்ஸ்ட்ரிங் சமநிலைக்கு, அதாவது 0 அல்லது 1 க்கு வரைபடமாக்கினால், இதன் விளைவாக க்யூபிட்களின் எண்ணிக்கையிலிருந்து சுயாதீனமாக நீளம் 2 நிகழ்தகவு திசையன் இருக்கும்.
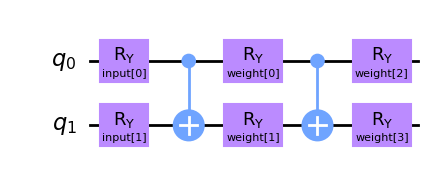
இந்த வழக்கில், நாம் இரு உள்ளீட்டு அளபுருக்கள் மற்றும் நான்கு சுற்றுச்சூழல் வீட்டில் இரண்டு உள்ளீட்டு சுற்றுப்பயணத்தை உருவாக்க வேண்டும்.
[29]:
from qiskit.circuit import ParameterVector
inputs2 = ParameterVector("input", 2)
weights2 = ParameterVector("weight", 4)
print(f"input parameters: {[str(item) for item in inputs2.params]}")
print(f"weight parameters: {[str(item) for item in weights2.params]}")
qc2 = QuantumCircuit(2)
qc2.ry(inputs2[0], 0)
qc2.ry(inputs2[1], 1)
qc2.cx(0, 1)
qc2.ry(weights2[0], 0)
qc2.ry(weights2[1], 1)
qc2.cx(0, 1)
qc2.ry(weights2[2], 0)
qc2.ry(weights2[3], 1)
qc2.draw(output="mpl")
input parameters: ['input[0]', 'input[1]']
weight parameters: ['weight[0]', 'weight[1]', 'weight[2]', 'weight[3]']
[29]:
அப்படியே ` ` சம்ப்லர் QNN ` ` ` சம்ப்ரீக்னென் ` ` . இந்த வழக்கில், விசைப்பெயர் வார்த்தைகள் ` ` samplerQNN ` ` ` ` samplerQNN ` `: விருப்பத் தன்மையான உதாரணம் ` ` input_params ` `: list of quantum circuit parameters that should be to be with "network inputs"- ` weight_ params ` `: list of quantum circuit parameters that should be to be with "network weights"
தயவு செய்து, மீண்டும் ஒரு முறை, நாங்கள் QNN க்கு ` ` சாம்பலர் ` ` உதாரணம் அமைக்க இல்லையென்றால், முன்னிருப்பில் மறுபடியும் தேர்ந்தெடுக்கப்படவில்லை.
[30]:
from qiskit_machine_learning.neural_networks import SamplerQNN
sampler_qnn = SamplerQNN(circuit=qc2, input_params=inputs2, weight_params=weights2)
sampler_qnn
[30]:
<qiskit_machine_learning.neural_networks.sampler_qnn.SamplerQNN at 0x7fd659264880>
மேலே காட்டப்பட்ட அடிப்படை தருமதிப்புகளின் கூடுதலாக, ` சம்ப்லர் QNN ` இன்னும் மூன்று அமைப்புகளை ஏற்றுக்கொள்கிறது: ` ` input_gradients-action ` `, and ` output_shape ` `. இவை 4 மற்றும் 5 பகுதிகளில் அறிமுகப்படுத்தப்படும்.
3. முன்னோக்கி பாஸை எவ்வாறு இயக்குவது#
3.1 அமைவு#
உண்மையான அமைப்பில், உள்ளீடுகள் தரவுத்தொகுப்பால் வரையறுக்கப்படும், மேலும் எடைகள் பயிற்சி அல்காரிதம் அல்லது முன் பயிற்சி பெற்ற மாதிரியின் ஒரு பகுதியாக வரையறுக்கப்படும். இருப்பினும், இந்த டுடோரியலுக்காக, சரியான பரிமாணத்தின் உள்ளீடு மற்றும் எடைகளின் சீரற்ற தொகுப்புகளை நாங்கள் குறிப்பிடுவோம்:
3.1.1.`` EstimatorQNN `` எடுத்துக்காட்டு#
[31]:
estimator_qnn_input = algorithm_globals.random.random(estimator_qnn.num_inputs)
estimator_qnn_weights = algorithm_globals.random.random(estimator_qnn.num_weights)
[32]:
print(
f"Number of input features for EstimatorQNN: {estimator_qnn.num_inputs} \nInput: {estimator_qnn_input}"
)
print(
f"Number of trainable weights for EstimatorQNN: {estimator_qnn.num_weights} \nWeights: {estimator_qnn_weights}"
)
Number of input features for EstimatorQNN: 1
Input: [0.77395605]
Number of trainable weights for EstimatorQNN: 1
Weights: [0.43887844]
3.1.2. SamplerQNN எடுத்துக்காட்டு#
[33]:
sampler_qnn_input = algorithm_globals.random.random(sampler_qnn.num_inputs)
sampler_qnn_weights = algorithm_globals.random.random(sampler_qnn.num_weights)
[34]:
print(
f"Number of input features for SamplerQNN: {sampler_qnn.num_inputs} \nInput: {sampler_qnn_input}"
)
print(
f"Number of trainable weights for SamplerQNN: {sampler_qnn.num_weights} \nWeights: {sampler_qnn_weights}"
)
Number of input features for SamplerQNN: 2
Input: [0.85859792 0.69736803]
Number of trainable weights for SamplerQNN: 4
Weights: [0.09417735 0.97562235 0.7611397 0.78606431]
எங்களிடம் உள்ளீடுகள் மற்றும் எடைகள் கிடைத்ததும், பேட்ச் மற்றும் பேட்ச் அல்லாத பாஸ்களுக்கான முடிவுகளைப் பார்ப்போம்.
3.2 தொகுதி அல்லாத முன்னோக்கி பாஸ்#
3.2.1. EstimatorQNN எடுத்துக்காட்டு#
EstimatorQNN``க்கு, முன்னோக்கி பாஸிற்கான எதிர்பார்க்கப்படும் வெளியீட்டு வடிவம் ``(1, num_qubits * num_observables) ஆகும், இங்கு 1 என்பது மாதிரிகளின் எண்ணிக்கை:
[35]:
estimator_qnn_forward = estimator_qnn.forward(estimator_qnn_input, estimator_qnn_weights)
print(
f"Forward pass result for EstimatorQNN: {estimator_qnn_forward}. \nShape: {estimator_qnn_forward.shape}"
)
Forward pass result for EstimatorQNN: [[0.2970094]].
Shape: (1, 1)
3.2.2. SamplerQNN எடுத்துக்காட்டு#
SamplerQNN (தனிப்பயன் விளக்கம் செயல்பாடு இல்லாமல்), முன்னோக்கி பாஸிற்கான எதிர்பார்க்கப்படும் வெளியீடு வடிவம் (1, 2**num_qubits) ஆகும். தனிப்பயன் விளக்கச் செயல்பாட்டின் மூலம், வெளியீட்டு வடிவம் (1, output_shape) ஆக இருக்கும், இங்கு 1 என்பது மாதிரிகளின் எண்ணிக்கை:
[36]:
sampler_qnn_forward = sampler_qnn.forward(sampler_qnn_input, sampler_qnn_weights)
print(
f"Forward pass result for SamplerQNN: {sampler_qnn_forward}. \nShape: {sampler_qnn_forward.shape}"
)
Forward pass result for SamplerQNN: [[0.01826527 0.25735654 0.5267981 0.19758009]].
Shape: (1, 4)
3.3 பேட்ச்டு ஃபார்வர்டு பாஸ்#
3.3.1. EstimatorQNN எடுத்துக்காட்டு#
EstimatorQNN``க்கு, முன்னோக்கி பாஸிற்கான எதிர்பார்க்கப்படும் வெளியீட்டு வடிவம் ``(batch_size, num_qubits * num_observables):
[37]:
estimator_qnn_forward_batched = estimator_qnn.forward(
[estimator_qnn_input, estimator_qnn_input], estimator_qnn_weights
)
print(
f"Forward pass result for EstimatorQNN: {estimator_qnn_forward_batched}. \nShape: {estimator_qnn_forward_batched.shape}"
)
Forward pass result for EstimatorQNN: [[0.2970094]
[0.2970094]].
Shape: (2, 1)
3.3.2. ` ` SamplerQNN ` எடுத்துக்காட்டு#
` ` SamplerQNN ` ` (தனிப்பட்ட விளக்க செயல்கூறு இல்லாமல்), எதிர்பார்க்கப்பட்ட வெளியீடு வடிவம் ` ` (batch_size, 2 * *num_qubits) ` `. With a custom interpret function, the output shape will be ` (batch_size, output_shape) ` `.
[38]:
sampler_qnn_forward_batched = sampler_qnn.forward(
[sampler_qnn_input, sampler_qnn_input], sampler_qnn_weights
)
print(
f"Forward pass result for SamplerQNN: {sampler_qnn_forward_batched}. \nShape: {sampler_qnn_forward_batched.shape}"
)
Forward pass result for SamplerQNN: [[0.01826527 0.25735654 0.5267981 0.19758009]
[0.01826527 0.25735654 0.5267981 0.19758009]].
Shape: (2, 4)
4. எப்படி ஒரு பின்னணி பாஸ் இயக்குவது#
பின்தங்கிய பாஸ் எவ்வாறு செயல்படுகிறது என்பதைக் காட்ட மேலே வரையறுக்கப்பட்ட உள்ளீடுகள் மற்றும் எடைகளைப் பயன்படுத்திக் கொள்வோம். இந்த பாஸ் ஒரு டூப்பிள் (உள்ளீடு_கிரேடியண்ட்ஸ், எடை_கிரேடியண்ட்ஸ்) வழங்கும். முன்னிருப்பாக, பின்தங்கிய பாஸ் எடை அளவுருக்கள் தொடர்பான சாய்வுகளை மட்டுமே கணக்கிடும்.
நீங்கள் உள்ளீட்டு அளபுருக்களுக்கு மதிப்புடன் சாங்குகளை செயலாக்க விரும்பினால், QNN instantiation க்குள் பின்வரும் குறியை அமைக்க வேண்டும்:
qnn = ...QNN(..., input_gradients=True)
தயவு செய்து நினைவில் கொள்ளும்படி உள்ளீட்டு சாதனங்கள் ** ` TorchConnector ` ` ` ` TorchConnector ` ` இன் பயன்பாடு.
4.1 உள்ளீடு சரிவுகள் இல்லாமல் பின்தங்கிய பாஸ்#
4.1.1. ` ` EstimatorQNN ` எடுத்துக்காட்டு#
` ` EstimatorQNN ` `, எடை சார்ந்துகளுக்கு எதிர்பார்க்கப்பட்ட வெளியீடு வடிவம் ` ` (batch_size, num_qubits * num_observables, num_weights) ` `:
[39]:
estimator_qnn_input_grad, estimator_qnn_weight_grad = estimator_qnn.backward(
estimator_qnn_input, estimator_qnn_weights
)
print(
f"Input gradients for EstimatorQNN: {estimator_qnn_input_grad}. \nShape: {estimator_qnn_input_grad}"
)
print(
f"Weight gradients for EstimatorQNN: {estimator_qnn_weight_grad}. \nShape: {estimator_qnn_weight_grad.shape}"
)
Input gradients for EstimatorQNN: None.
Shape: None
Weight gradients for EstimatorQNN: [[[0.63272767]]].
Shape: (1, 1, 1)
4.1.2. ` ` SamplerQNN ` எடுத்துக்காட்டு#
` ` SamplerQNN ` ` (தனிப்பட்ட விளக்கச்சீட்டு செயல்கூறு இல்லாமல்), முன்னோடியான வெளியீட்டு வடிவம் ` ` (batch_size, 2 * *num_qubits, num_weights) ` `. தனிப்பயன் வடிவமைப்புடன் வெளியீட்டு வடிவம் ` ` (batch_size, output_shape, num_weights) ` `.:
[40]:
sampler_qnn_input_grad, sampler_qnn_weight_grad = sampler_qnn.backward(
sampler_qnn_input, sampler_qnn_weights
)
print(
f"Input gradients for SamplerQNN: {sampler_qnn_input_grad}. \nShape: {sampler_qnn_input_grad}"
)
print(
f"Weight gradients for SamplerQNN: {sampler_qnn_weight_grad}. \nShape: {sampler_qnn_weight_grad.shape}"
)
Input gradients for SamplerQNN: None.
Shape: None
Weight gradients for SamplerQNN: [[[ 0.00606238 -0.1124595 -0.06856156 -0.09809236]
[ 0.21167414 -0.09069775 0.06856156 -0.22549618]
[-0.48846674 0.32499215 -0.32262178 0.09809236]
[ 0.27073021 -0.12183491 0.32262178 0.22549618]]].
Shape: (1, 4, 4)
4.2 உள்ளீட்டு சாய்வுகளுடன் பின்தங்கிய பாஸ்#
எதிர்பார்க்கப்பட்ட வெளியீட்டுக் அளவுகள் இந்த விருப்பத்துக்கு என்ன ` ` input_gradients - > ` ` ` input_gradients-action
[41]:
estimator_qnn.input_gradients = True
sampler_qnn.input_gradients = True
4.2.1. ` ` EstimatorQNN ` எடுத்துக்காட்டு#
` ` EstimatorQNN ` `, உள்ளீட்டு சாதனங்களுக்கான எதிர்பார்க்கப்பட்ட வெளியீடு வடிவம் ` ` (batch_size, num_qubits * num_observables, num_inputs) ` `:
[42]:
estimator_qnn_input_grad, estimator_qnn_weight_grad = estimator_qnn.backward(
estimator_qnn_input, estimator_qnn_weights
)
print(
f"Input gradients for EstimatorQNN: {estimator_qnn_input_grad}. \nShape: {estimator_qnn_input_grad.shape}"
)
print(
f"Weight gradients for EstimatorQNN: {estimator_qnn_weight_grad}. \nShape: {estimator_qnn_weight_grad.shape}"
)
Input gradients for EstimatorQNN: [[[0.3038852]]].
Shape: (1, 1, 1)
Weight gradients for EstimatorQNN: [[[0.63272767]]].
Shape: (1, 1, 1)
4.2.2. ` ` SamplerQNN ` எடுத்துக்காட்டு#
` ` SamplerQNN ` ` (தனிப்பட்ட விளக்க செயல்கூறு இல்லாமல்), உள்ளீட்டு சாதனங்களுக்கான எதிர்பார்க்கப்பட்ட வெளியீடு வடிவம் ` ` (batch_size, 2 * *num_qubits, num_inputs) ` `. தனிப்பயன் வடிவமைப்புடன் வெளியீட்டு வடிவம் ` ` (batch_size, output_shape, num_inputs) ` `.
[43]:
sampler_qnn_input_grad, sampler_qnn_weight_grad = sampler_qnn.backward(
sampler_qnn_input, sampler_qnn_weights
)
print(
f"Input gradients for SamplerQNN: {sampler_qnn_input_grad}. \nShape: {sampler_qnn_input_grad.shape}"
)
print(
f"Weight gradients for SamplerQNN: {sampler_qnn_weight_grad}. \nShape: {sampler_qnn_weight_grad.shape}"
)
Input gradients for SamplerQNN: [[[-0.05844702 -0.10621091]
[ 0.38798796 -0.19544083]
[-0.34561132 0.09459601]
[ 0.01607038 0.20705573]]].
Shape: (1, 4, 2)
Weight gradients for SamplerQNN: [[[ 0.00606238 -0.1124595 -0.06856156 -0.09809236]
[ 0.21167414 -0.09069775 0.06856156 -0.22549618]
[-0.48846674 0.32499215 -0.32262178 0.09809236]
[ 0.27073021 -0.12183491 0.32262178 0.22549618]]].
Shape: (1, 4, 4)
5. மேம்பட்ட செயல்பாடுகள்#
5.1 EstimatorQNN பல அவதானிப்புகளுடன்#
` ` EstimatorQNN ` ` மேலும் சிக்கலான QNN கட்டிடக்கலுக்கான ஆவணங்களின் பட்டியல்களை கடக்க அனுமதிக்கிறது. உதாரணமாக (வெளியீட்டு வடிவத்தில் மாற்றம் குறிப்பு):
[44]:
observable2 = SparsePauliOp.from_list([("Z" * qc1.num_qubits, 1)])
estimator_qnn2 = EstimatorQNN(
circuit=qc1,
observables=[observable1, observable2],
input_params=[params1[0]],
weight_params=[params1[1]],
)
[45]:
estimator_qnn_forward2 = estimator_qnn2.forward(estimator_qnn_input, estimator_qnn_weights)
estimator_qnn_input_grad2, estimator_qnn_weight_grad2 = estimator_qnn2.backward(
estimator_qnn_input, estimator_qnn_weights
)
print(f"Forward output for EstimatorQNN1: {estimator_qnn_forward.shape}")
print(f"Forward output for EstimatorQNN2: {estimator_qnn_forward2.shape}")
print(f"Backward output for EstimatorQNN1: {estimator_qnn_weight_grad.shape}")
print(f"Backward output for EstimatorQNN2: {estimator_qnn_weight_grad2.shape}")
Forward output for EstimatorQNN1: (1, 1)
Forward output for EstimatorQNN2: (1, 2)
Backward output for EstimatorQNN1: (1, 1, 1)
Backward output for EstimatorQNN2: (1, 2, 1)
5. 2. ` ` SamplerQNN ` ` தனிப்பயன் ` ` ` `#
ஒரு பொதுவான ` ` சம்ப்லர் QNN ` ` என்ற முறையை ` ` parity ` ` என்ற முறையில், இது இரும வகைப்பாட்டை செயல்படுத்துவதற்கு அனுமதிக்கிறது. எடுத்துக்காட்டு விகிதத்தில் விளக்கப்படாமல், விளக்கச் செயல்களைப் பயன்படுத்தி முன்னணி மற்றும் பின்னூட்டிகளின் வெளியீட்டு வடிவத்தை மாற்றும். பார்சி உரையாடல் செயல்கூறு, ` ` output_shape ` ` ` ` output_shape ` `. அதனால், எதிர்பார்க்கப்பட்ட முன்னேற்றம் மற்றும் எடை கிரீடென்ட் வடிவங்கள் ` ` (batch_size, 2) ` ` (batch_size, 2, num_weights) ` ` ` Batch_size, 2, num_weights) `.
[46]:
parity = lambda x: "{:b}".format(x).count("1") % 2
output_shape = 2 # parity = 0, 1
sampler_qnn2 = SamplerQNN(
circuit=qc2,
input_params=inputs2,
weight_params=weights2,
interpret=parity,
output_shape=output_shape,
)
[47]:
sampler_qnn_forward2 = sampler_qnn2.forward(sampler_qnn_input, sampler_qnn_weights)
sampler_qnn_input_grad2, sampler_qnn_weight_grad2 = sampler_qnn2.backward(
sampler_qnn_input, sampler_qnn_weights
)
print(f"Forward output for SamplerQNN1: {sampler_qnn_forward.shape}")
print(f"Forward output for SamplerQNN2: {sampler_qnn_forward2.shape}")
print(f"Backward output for SamplerQNN1: {sampler_qnn_weight_grad.shape}")
print(f"Backward output for SamplerQNN2: {sampler_qnn_weight_grad2.shape}")
Forward output for SamplerQNN1: (1, 4)
Forward output for SamplerQNN2: (1, 2)
Backward output for SamplerQNN1: (1, 4, 4)
Backward output for SamplerQNN2: (1, 2, 4)
6. முடிவுரை#
இந்த டுடோரியலில், கிஸ்கிட்-மெஷின்-லேர்னிங் வழங்கும் இரண்டு நரம்பியல் நெட்வொர்க்குகள் வகுப்புகளை அறிமுகப்படுத்தினோம், அதாவது EstimatorQNN மற்றும் SamplerQNN, இது அடிப்படை NeuralNetwork வகுப்பை விரிவுபடுத்துகிறது. நாங்கள் சில கோட்பாட்டு பின்னணி, QNN துவக்கத்திற்கான முக்கிய படிகள், முன்னோக்கி மற்றும் பின்தங்கிய பாஸ்களில் அடிப்படை பயன்பாடு மற்றும் மேம்பட்ட செயல்பாடுகளை வழங்கினோம்.
சிக்கல் அமைப்பைச் சுற்றி விளையாடவும், வெவ்வேறு சுற்று அளவுகள், உள்ளீடு மற்றும் எடை அளவுரு நீளங்கள் வெளியீட்டு வடிவங்களை எவ்வாறு பாதிக்கின்றன என்பதைப் பார்க்கவும் நாங்கள் இப்போது உங்களை ஊக்குவிக்கிறோம்.
[48]:
import qiskit.tools.jupyter
%qiskit_version_table
%qiskit_copyright
Version Information
| Qiskit Software | Version |
|---|---|
qiskit-terra | 0.22.3 |
qiskit-machine-learning | 0.6.0 |
| System information | |
| Python version | 3.9.15 |
| Python compiler | Clang 14.0.6 |
| Python build | main, Nov 24 2022 08:29:02 |
| OS | Darwin |
| CPUs | 8 |
| Memory (Gb) | 64.0 |
| Mon Jan 23 11:57:49 2023 CET | |
This code is a part of Qiskit
© Copyright IBM 2017, 2023.
This code is licensed under the Apache License, Version 2.0. You may
obtain a copy of this license in the LICENSE.txt file in the root directory
of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
Any modifications or derivative works of this code must retain this
copyright notice, and modified files need to carry a notice indicating
that they have been altered from the originals.