Nota
Esta página fue generada a partir de docs/tutorials/09_saving_and_loading_models.ipynb.
Guardar, Cargar Modelos de Qiskit Machine Learning y Entrenamiento Continuo#
En este tutorial, mostraremos cómo guardar y cargar modelos de machine learning de Qiskit. La capacidad de guardar un modelo es muy importante, especialmente cuando se invierte una cantidad significativa de tiempo en entrenar un modelo en un hardware real. Además, mostraremos cómo reanudar el entrenamiento del modelo previamente guardado.
En este tutorial cubriremos cómo:
Generar un conjunto de datos simple, dividirlo en conjuntos de datos de entrenamiento/prueba y graficarlos
Entrenar y guardar un modelo
Cargar un modelo guardado y reanudar el entrenamiento
Evaluar el rendimiento de los modelos
Modelos híbridos de PyTorch
En primer lugar, comenzamos con las importaciones requeridas. Usaremos mucho SciKit-Learn en el paso de preparación de datos. En la siguiente celda también fijamos una semilla aleatoria con fines de reproducibilidad.
[1]:
import matplotlib.pyplot as plt
import numpy as np
from qiskit.circuit.library import RealAmplitudes
from qiskit.primitives import Sampler
from qiskit_algorithms.optimizers import COBYLA
from qiskit_algorithms.utils import algorithm_globals
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder, MinMaxScaler
from qiskit_machine_learning.algorithms.classifiers import VQC
from IPython.display import clear_output
algorithm_globals.random_seed = 42
Usaremos dos simuladores cuánticos, en particular, dos instancias de la primitiva Sampler. Comenzaremos a entrenar en la primera, luego reanudaremos el entrenamiento en la segunda. El enfoque que se muestra en este tutorial se puede usar para entrenar un modelo en un hardware real disponible en la nube y luego reutilizar el modelo para la inferencia en un simulador local.
[2]:
sampler1 = Sampler()
sampler2 = Sampler()
1. Preparar un conjunto de datos#
El siguiente paso es preparar un conjunto de datos. Aquí, generamos algunos datos de la misma manera que en otros tutoriales. La diferencia es que aplicamos algunas transformaciones a los datos generados. Generamos 40 muestras, cada muestra tiene 2 características, por lo que nuestras características son una matriz de la forma (40, 2). Las etiquetas se obtienen sumando características por columnas y si la suma es mayor que 1, esta muestra se etiqueta como 1 y 0 en caso contrario.
[3]:
num_samples = 40
num_features = 2
features = 2 * algorithm_globals.random.random([num_samples, num_features]) - 1
labels = 1 * (np.sum(features, axis=1) >= 0) # in { 0, 1}
Luego, reducimos nuestras características a un rango de [0, 1] aplicando MinMaxScaler de SciKit-Learn. La convergencia de entrenamiento de modelos es mejor cuando se aplica esta transformación.
[4]:
features = MinMaxScaler().fit_transform(features)
features.shape
[4]:
(40, 2)
Echemos un vistazo a las características de las primeras 5 muestras de nuestro conjunto de datos después de la transformación.
[5]:
features[0:5, :]
[5]:
array([[0.79067335, 0.44566143],
[0.88072937, 0.7126244 ],
[0.06741233, 1. ],
[0.7770372 , 0.80422817],
[0.10351936, 0.45754615]])
Elegimos VQC o Clasificador Cuántico Variacional (Variational Quantum Classifier) como un modelo que entrenaremos. Este modelo, por defecto, toma etiquetas codificadas en one-hot, por lo que tenemos que transformar las etiquetas que están en el conjunto de {0, 1} en una representación en one-hot. También empleamos SciKit-Learn para esta transformación. Ten en cuenta que la matriz de entrada debe cambiarse primero a la forma (num_samples, 1). El codificador OneHotEncoder no funciona con arreglos 1D y nuestras etiquetas son un arreglo 1D. En este caso, un usuario debe decidir si un arreglo tiene solo una característica (¡nuestro caso!) o tiene una muestra. Además, de manera predeterminada, el codificador devuelve arreglos dispersos, pero para la graficación de conjuntos de datos es más fácil tener arreglos densos, por lo que configuramos sparse con False.
[6]:
labels = OneHotEncoder(sparse_output=False).fit_transform(labels.reshape(-1, 1))
labels.shape
[6]:
(40, 2)
Echemos un vistazo a las etiquetas de las primeras 5 del conjunto de datos. Las etiquetas deben estar codificadas en one-hot.
[7]:
labels[0:5, :]
[7]:
array([[0., 1.],
[0., 1.],
[0., 1.],
[0., 1.],
[1., 0.]])
Ahora dividimos nuestro conjunto de datos en dos partes: un conjunto de datos de entrenamiento y uno de prueba. Como regla general, el 80% de un conjunto de datos completo debe ir a una parte de entrenamiento y el 20% a una de prueba. Nuestro conjunto de datos de entrenamiento tiene 30 muestras. El conjunto de datos de prueba debe usarse solo una vez, cuando se entrena un modelo para verificar qué tan bien se comporta el modelo en datos no vistos. Empleamos train_test_split de SciKit-Learn.
[8]:
train_features, test_features, train_labels, test_labels = train_test_split(
features, labels, train_size=30, random_state=algorithm_globals.random_seed
)
train_features.shape
[8]:
(30, 2)
Ahora es el momento de ver cómo es nuestro conjunto de datos. Vamos a graficarlo.
[9]:
def plot_dataset():
plt.scatter(
train_features[np.where(train_labels[:, 0] == 0), 0],
train_features[np.where(train_labels[:, 0] == 0), 1],
marker="o",
color="b",
label="Label 0 train",
)
plt.scatter(
train_features[np.where(train_labels[:, 0] == 1), 0],
train_features[np.where(train_labels[:, 0] == 1), 1],
marker="o",
color="g",
label="Label 1 train",
)
plt.scatter(
test_features[np.where(test_labels[:, 0] == 0), 0],
test_features[np.where(test_labels[:, 0] == 0), 1],
marker="o",
facecolors="w",
edgecolors="b",
label="Label 0 test",
)
plt.scatter(
test_features[np.where(test_labels[:, 0] == 1), 0],
test_features[np.where(test_labels[:, 0] == 1), 1],
marker="o",
facecolors="w",
edgecolors="g",
label="Label 1 test",
)
plt.legend(bbox_to_anchor=(1.05, 1), loc="upper left", borderaxespad=0.0)
plt.plot([1, 0], [0, 1], "--", color="black")
plot_dataset()
plt.show()
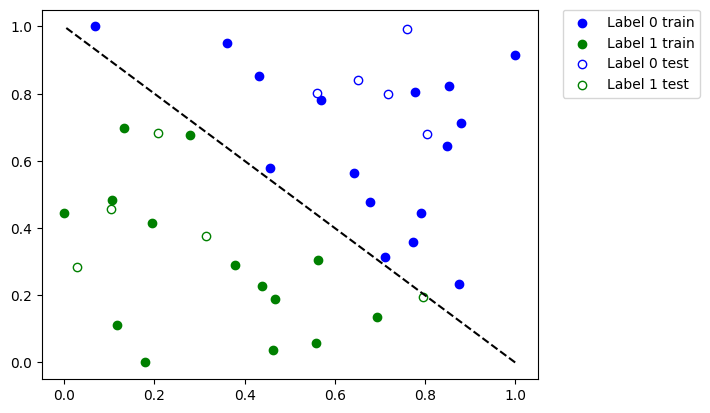
En la gráfica de arriba vemos:
Los puntos azules sólidos son las muestras del conjunto de datos de entrenamiento etiquetados como
0Los puntos azules vacíos son las muestras del conjunto de datos de prueba etiquetados como
0Los puntos verdes sólidos son las muestras del conjunto de datos de entrenamiento etiquetados como
1Los puntos verdes vacíos son las muestras del conjunto de datos de prueba etiquetados como
1
Entrenaremos nuestro modelo usando los puntos sólidos y lo verificaremos usando los puntos vacíos.
2. Entrenar un modelo y guardarlo#
Entrenaremos nuestro modelo en dos pasos. En el primer paso entrenamos nuestro modelo en 20 iteraciones.
[10]:
maxiter = 20
Crea un arreglo vacío para que la devolución de llamada almacene los valores de la función objetivo.
[11]:
objective_values = []
Reutilizamos una función de devolución de llamada del tutorial Redes Neuronales de Clasificación y Regresión para graficar la iteración contra el valor de la función objetivo con algunos ajustes menores para graficar los valores objetivos en cada paso.
[12]:
# callback function that draws a live plot when the .fit() method is called
def callback_graph(_, objective_value):
clear_output(wait=True)
objective_values.append(objective_value)
plt.title("Objective function value against iteration")
plt.xlabel("Iteration")
plt.ylabel("Objective function value")
stage1_len = np.min((len(objective_values), maxiter))
stage1_x = np.linspace(1, stage1_len, stage1_len)
stage1_y = objective_values[:stage1_len]
stage2_len = np.max((0, len(objective_values) - maxiter))
stage2_x = np.linspace(maxiter, maxiter + stage2_len - 1, stage2_len)
stage2_y = objective_values[maxiter : maxiter + stage2_len]
plt.plot(stage1_x, stage1_y, color="orange")
plt.plot(stage2_x, stage2_y, color="purple")
plt.show()
plt.rcParams["figure.figsize"] = (12, 6)
Como se mencionó anteriormente, entrenamos un modelo VQC y configuramos COBYLA como un optimizador con un valor dado del parámetro maxiter. Luego evaluamos el desempeño del modelo para ver qué tan bien fue entrenado. Después guardamos este modelo en un archivo. En el segundo paso cargamos este modelo y continuaremos trabajando con él.
Aquí, construimos manualmente un ansatz para fijar un punto inicial desde donde comenzar la optimización.
[13]:
original_optimizer = COBYLA(maxiter=maxiter)
ansatz = RealAmplitudes(num_features)
initial_point = np.asarray([0.5] * ansatz.num_parameters)
Creamos un modelo y configuramos el sampler con el primer sampler que creamos anteriormente.
[14]:
original_classifier = VQC(
ansatz=ansatz, optimizer=original_optimizer, callback=callback_graph, sampler=sampler1
)
Ahora es el momento de entrenar el modelo.
[15]:
original_classifier.fit(train_features, train_labels)
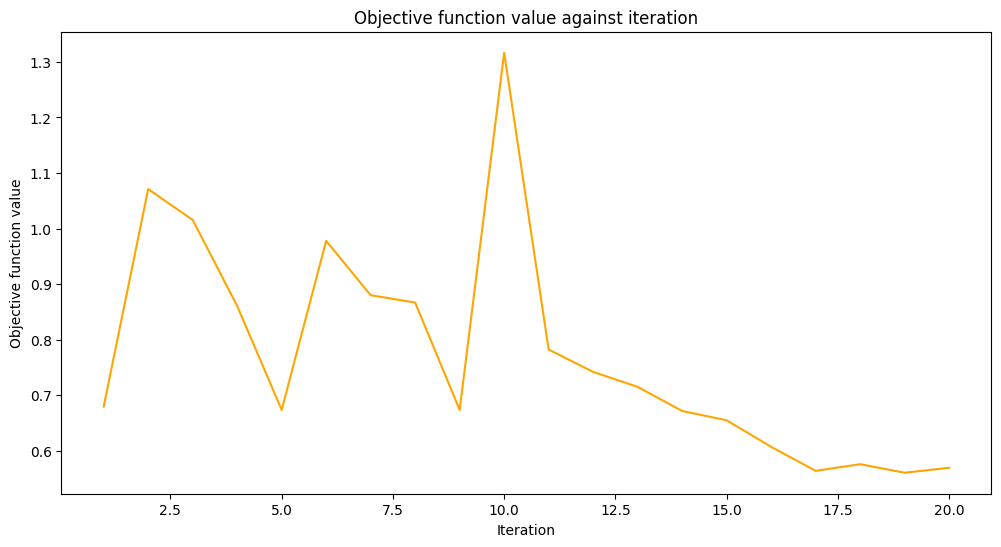
[15]:
<qiskit_machine_learning.algorithms.classifiers.vqc.VQC at 0x7fb74126db20>
Veamos qué tan bien funciona nuestro modelo después del primer paso de entrenamiento.
[16]:
print("Train score", original_classifier.score(train_features, train_labels))
print("Test score ", original_classifier.score(test_features, test_labels))
Train score 0.8333333333333334
Test score 0.8
A continuación, guardamos el modelo. Puedes elegir cualquier nombre de archivo que desees. Ten en cuenta que el método save no agrega una extensión si no se especifica en el nombre del archivo.
[17]:
original_classifier.save("vqc_classifier.model")
3. Cargar un modelo y continuar su entrenamiento#
Para cargar un modelo, un usuario debe llamar al método load de la clase del modelo correspondiente. En nuestro caso es VQC. Le pasamos el mismo nombre de archivo que usamos en el apartado anterior donde guardamos nuestro modelo.
[18]:
loaded_classifier = VQC.load("vqc_classifier.model")
A continuación, queremos modificar el modelo de manera que pueda entrenarse más y en otro simulador. Para hacerlo, establecemos la propiedad warm_start. Cuando se establece en True y se llama de nuevo a fit(), el modelo utiliza los pesos del ajuste anterior para iniciar un nuevo ajuste. También configuramos la propiedad sampler de la red subyacente a la segunda instancia de la primitiva Sampler que creamos al comienzo del tutorial. Finalmente, creamos y configuramos un nuevo optimizador con maxiter establecido en 80, por lo que el número total de iteraciones es 100.
[19]:
loaded_classifier.warm_start = True
loaded_classifier.neural_network.sampler = sampler2
loaded_classifier.optimizer = COBYLA(maxiter=80)
Ahora seguimos entrenando nuestro modelo desde el estado en el que terminamos en el apartado anterior.
[20]:
loaded_classifier.fit(train_features, train_labels)
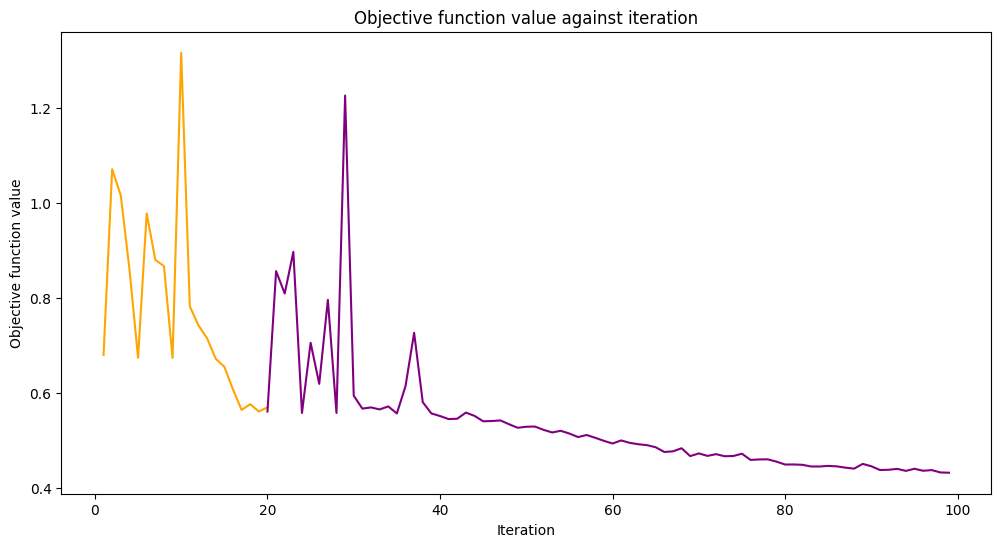
[20]:
<qiskit_machine_learning.algorithms.classifiers.vqc.VQC at 0x7fb7411cb760>
[21]:
print("Train score", loaded_classifier.score(train_features, train_labels))
print("Test score", loaded_classifier.score(test_features, test_labels))
Train score 0.9
Test score 0.8
Veamos qué puntos de datos se clasificaron incorrectamente. Primero, llamamos predict para inferir los valores predichos de las características de entrenamiento y prueba.
[22]:
train_predicts = loaded_classifier.predict(train_features)
test_predicts = loaded_classifier.predict(test_features)
Grafica el conjunto de datos completo y resaltar los puntos que se clasificaron incorrectamente.
[23]:
# return plot to default figsize
plt.rcParams["figure.figsize"] = (6, 4)
plot_dataset()
# plot misclassified data points
plt.scatter(
train_features[np.all(train_labels != train_predicts, axis=1), 0],
train_features[np.all(train_labels != train_predicts, axis=1), 1],
s=200,
facecolors="none",
edgecolors="r",
linewidths=2,
)
plt.scatter(
test_features[np.all(test_labels != test_predicts, axis=1), 0],
test_features[np.all(test_labels != test_predicts, axis=1), 1],
s=200,
facecolors="none",
edgecolors="r",
linewidths=2,
)
[23]:
<matplotlib.collections.PathCollection at 0x7fb6e04c2eb0>
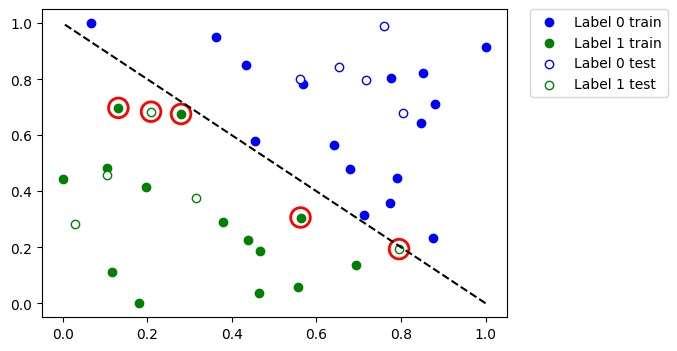
Por lo tanto, si tienes un conjunto de datos grande o un modelo grande, puedes entrenarlo en varios pasos como se muestra en este tutorial.
4. Modelos híbridos de PyTorch#
Para guardar y cargar modelos híbridos, al usar TorchConnector, sigue las recomendaciones de PyTorch para guardar y cargar los modelos. Para obtener más detalles, consulta el tutorial del Conector de PyTorch donde un breve fragmento de código muestra cómo hacerlo.
Echa un vistazo a este pseudo código para hacerte una idea:
# create a QNN and a hybrid model
qnn = create_qnn()
model = Net(qnn)
# ... train the model ...
# save the model
torch.save(model.state_dict(), "model.pt")
# create a new model
new_qnn = create_qnn()
loaded_model = Net(new_qnn)
loaded_model.load_state_dict(torch.load("model.pt"))
[24]:
import qiskit.tools.jupyter
%qiskit_version_table
%qiskit_copyright
Version Information
| Qiskit Software | Version |
|---|---|
qiskit-terra | 0.25.0 |
qiskit-aer | 0.13.0 |
qiskit-machine-learning | 0.7.0 |
| System information | |
| Python version | 3.8.13 |
| Python compiler | Clang 12.0.0 |
| Python build | default, Oct 19 2022 17:54:22 |
| OS | Darwin |
| CPUs | 10 |
| Memory (Gb) | 64.0 |
| Mon Jun 12 11:51:03 2023 IST | |
This code is a part of Qiskit
© Copyright IBM 2017, 2023.
This code is licensed under the Apache License, Version 2.0. You may
obtain a copy of this license in the LICENSE.txt file in the root directory
of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
Any modifications or derivative works of this code must retain this
copyright notice, and modified files need to carry a notice indicating
that they have been altered from the originals.